The MySQL database server can display a lot of performance statistics. However, most of them relate to general server parameters, such as buffer sizes and query cache settings. Of course, such settings are important to get right, and can make a huge difference in performance. Once you've tuned them however, you need to start looking at the tables and queries. When a single bad query can cost
90 - 99% of the total performance, server tuning doesn't fix the problem. But obtaining query profiling information from MySQL can be tricky. Here are some of the options:
Slow query log
You can use the built-in slow_query_log from within the server. It will show you queries that take more than a second. Such queries typically don't use indices properly and are important to address. But only slow queries end up there, and many performance problems aren't caused by slow queries, but by queries that are run very often (for example, for-loops in the code instead of JOINs). You could use complete server query logging. This will log every statement to file, but it's not recommended, as it will take too much disk I/O.
SHOW PROFILES
SHOW PROFILES command by Jeremy Cole (available from MySQL 5.0.37) can help you a great deal. Once enabled, it will gather cpu execution times and other important information on up to 100 queries. You can compare the results and see wich query is most expensive. This article explains more.
SHOW USER / INDEX / TABLE STATISTICS
The SHOW USER / INDEX / TABLE STATISTICS patches from Google add functionality to trace cpu time and much more per user, index and table. No query information is shown though, you will have to figure that out based on the tables. The patches are not part of the main MySQL distribution, but Percona provides prebuilt MySQL versions.
MySQL Enterprise Monitor's Query Analyzer
MySQL Enterprise Monitor's Query Analyzer is great for finding the heaviest queries. Using MySQL Proxy (man-in-the-middle software), it collects all queries sent to the server and ranks them by execution time. You can also see number of times the query was run, and number of rows typically returned. Being the best tool of them all, it also costs, and it requires additional software/hardware setup for the MySQL Proxy.
SHOW PROCESSLIST
Another option is the SHOW PROCESSLIST command. It shows a list of currently running processes (queries), slightly similar to the Unix ps command or Windows Task Manager. For every query, you can see how long the query has run, its user, ip and state. If you run this command just once, you will get a snapshot of what queries the server is busy doing right now. Aggregating multiple snapshots over time can give you a good view of what queries the server typically is busy performing. An advantage of SHOW PROCESSLIST is that it works on all MySQL versions without modifications and requires no additional software / hardware. On the downside, you don't necessarily catch all queries, just the queries that happen to run during every snapshot. If you collect many snapshots over long time, this is less of a problem.
Issues
You might not have the option to go for MySQL Enterprise, or install MySQL Proxy in front of your database servers. Or you might not be able to swith to the MySQL server versions containing Google's patches or SHOW PROFILES. Another problem is, that even if you do get profiling information, it is typically presented in raw text form, and might not be easy to browse through. Good tools to visualize the profiling information and navigate through the data is just as important as getting the information in the first place.
A new profiling tool
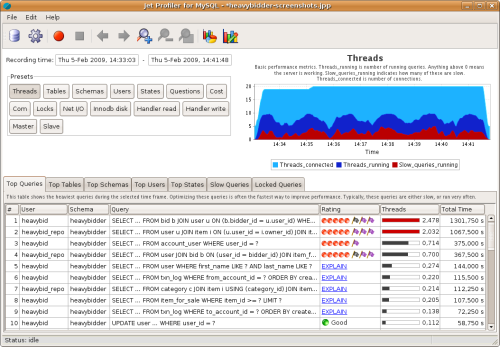
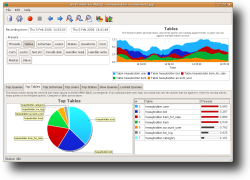
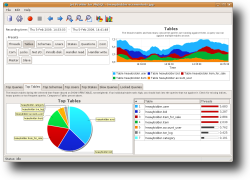 We're currently in the process of developing a tool based on the SHOW PROCESSLIST above. The tool, called Jet Profiler for MySQL, collects process list information and stores it in an internal database where it is analyzed, ranked and presented. After normalizing the queries, top lists are created of:
We're currently in the process of developing a tool based on the SHOW PROCESSLIST above. The tool, called Jet Profiler for MySQL, collects process list information and stores it in an internal database where it is analyzed, ranked and presented. After normalizing the queries, top lists are created of:
- most frequent queries
- most frequent users
- most frequent tables
- most frequent schemas
By looking at the state of the processes, additional information can be extracted, such as lock-prone queries (if you're using MyISAM tables), or queries which create a lot of temp tables on disk. The tool is a client desktop app so no server changes are required. It works on all MySQL versions (3.23 - 6.0).
Better visualization and usability
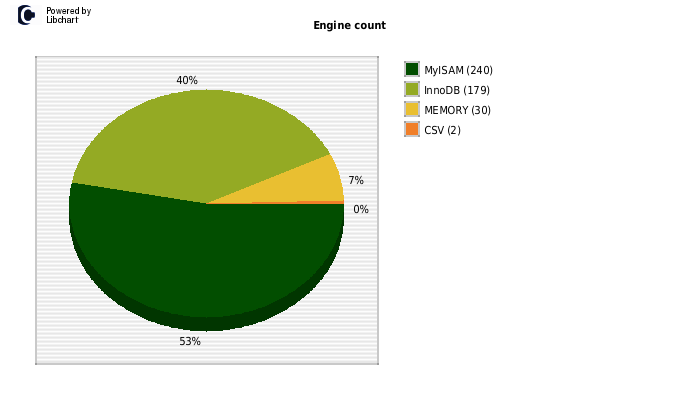
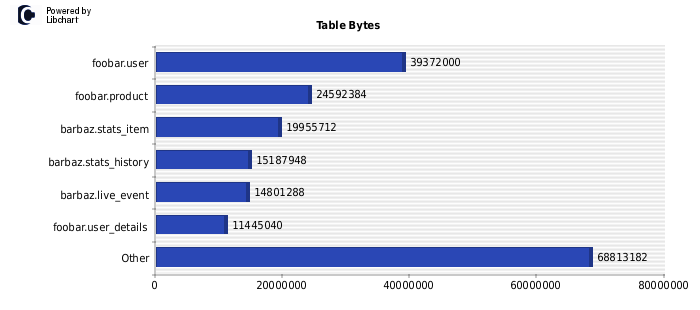
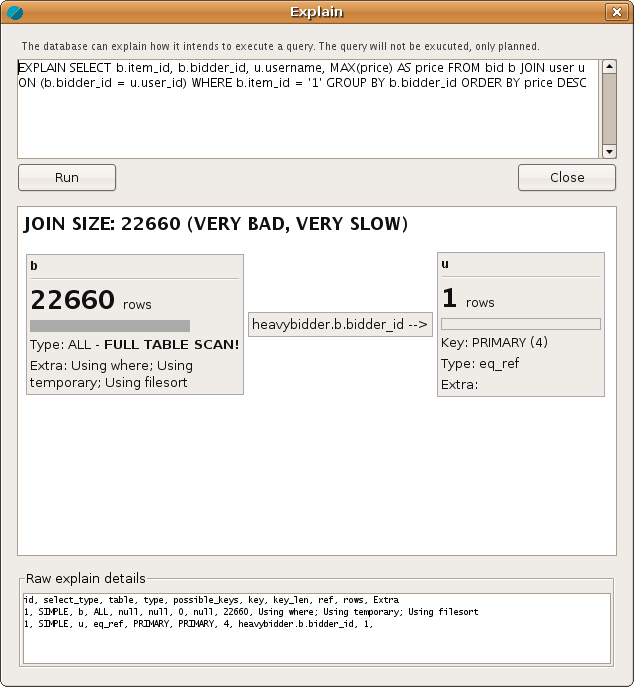
To provide good visualization, the information is presented in a line chart over time. You can zoom in on spikes and other interesting time intervals, and see the top queries / users / etc for that particular time frame. Every top list is accompanied by a pie chart to make it easier to compare the impact of different items. An experimental EXPLAIN visualization feature is underway, helping you understand the queries better.
Beta testers are welcome
We still have lots of adjustments and features before a public release, but we are looking beta testers. If you are interested, click here.
More information